A Large-scale Drug Name Dictionary Used to Analyze Drug Names in Real Clinical Settings
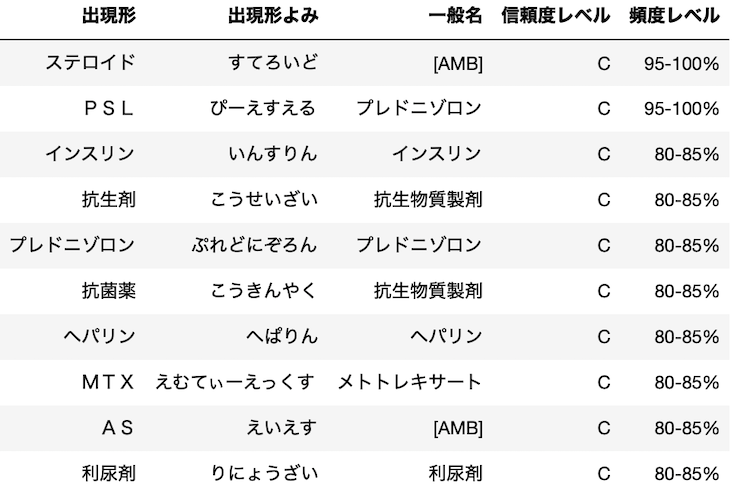
The process of extracting disease names and drug names from medical documents is carried out frequently in medical language processing research. However, in actual medical practice, abbreviations and English names for the drugs are often used instead of generic names for the drugs. Therefore, it is not possible to meet the demand for extracting all information on drugs using only standard names. Therefore, we have created data that can extract wider range of terms related to pharmaceuticals. We have named it “Hyakuyaku Dictionary”. This page contains download file for Hyakuyaku Dictionary and related data. Please use it freely.