ソーシャル・コンピューティング研究室では,大規模言語モデルをはじめとした自然言語処理やAI を用いて,医療健康,地理情報,法律など幅広い分野への応用や社会実装,情報技術を用いた心理学・ウェルビーイング研究,社会学研究を行っています.詳細な活動についてご興味がある方は,研究業績や研究室年報をご覧ください.
医療言語処理
AIの成果がもっとも期待されているドメインの1つが医療分野です.本研究室は,医療テキスト処理において世界をリードする成果を挙げ,国内の中心的存在です.常時,多くの共同研究,プロジェクトが走り,電子カルテテキスト,医学論文など大量の臨床データの大規模解析による医学研究を推進しています. 例えば,次のようなテーマをこれまで扱ってきました.
・大規模病名辞書の構築(内閣府SIP-統合型ヘルスケアシステムの構築):本邦最大規模の病名・医薬品・部位・検査に関する用語を収載した辞書を開発し,公開しています.
・総合診療(プライマリケア)を支援する症例検索システム(医師用診断支援システム;AMED研究による):日本内科学会の症例報告を利用し,診断支援を行う研究を行いました.
・患者の医師のコミュニケーションを支えるプラットフォーム(内閣府SIP-AIホスピタルプロジェクトによる):患者の発話を医療に有効利用するため,患者表現を理解する言語処理システムを研究開発しました.
・患者の自主報告を診療に活かす患者一行日記アプリ開発(京都大学,関西医科大学共同研究):スマートフォンアプリを用いて,患者発信のデータを診断に活かす研究をしています.
・認知症の超早期診断(京都大学,大阪国際がんセンター共同研究):患者の語り(文章や発話内容)から疾患の進行を予測や,感情を分類,悩みの分類,近い状態にある患者や介護者の推薦など様々なサポートを実現する研究を行っています.
・がん患者のピアサポートの場の形成(乳がん患者団体CANSOLとの共同研究):本研究室が共同運営するエピソードバンクとソーシャルネットワークサービスを用いて,がん患者さん同士が交流し,サポートする研究を行っています.
それぞれ,本邦を代表するステークホルダーと迫力のある規模で研究を推進しています.
ソーシャルメディア・Webデータで豊かな生活を
ソーシャルメディアやWeb上のビッグデータを活用した,様々な研究を行っています.詳しくは論文発表を御覧ください.
- ライブストリーミング配信テキストにおける暴言の特定と分類
- SNSにおける名誉毀損発言の解析
- Twitterを用いた街の雰囲気情報の抽出
- 家族介護者の悩みの解析
異分野との協働:個人と場のWell-beingを計測する
個人と集団(場)のwell-beingの両方を満たしたい.この大きな課題に挑むため,社会心理学,都市デザインなどの異分野の研究者と共同研究しています.我々は,多様な個人の最適化は,その基盤となっている「場」によって支えられるという立場をとっています.そのため,「場」の状態を計測する技術を開発し,それを個人にフィードバックする新しい社会のあり方を研究しています.(共同研究先:京都大学,東京大学)
遺伝的な不安をケアするカウンセリング支援
遺伝学の目覚ましい発展により,遺伝が健康に大きく関連することが明らかになってきました.それに伴い,遺伝に関わる悩みや不安を相談するカウンセリング(遺伝カウンセリング)の需要が増加しています.本研究室では,大規模言語モデル(LLM)による遺伝カウンセリング対話支援の研究に取り組んでいます.特に,眼科における遺伝カウンセリングやLLMの医療における安全性に注力しており,医療機関での対話システムの実用化を目指しています.(共同研究先:株式会社ビジョンケア,神戸アイセンター病院)
理想と現実のボディイメージの数理モデル化
日本の成人女性のやせの割合は,先進国の中で最も高くなっています.これは,太っていなくても「太っている」と過大評価してしまうために,無理なダイエットを繰り返してしまうことが原因の一つであると考えます.そこで,理想のBMIがどのように推移していくのかを探索します.そのために,理想BMI推移をシミュレーションし,ダイエットによる理想BMIの最終目標を明らかにします.(共同研究先:花王株式会社)
テキストからヘルスケア情報を抽出する
言語モデルを用いて,医療文書やソーシャルメディアテキストからのヘルスケア関連情報の抽出に取り組んでいます.例えば,電子カルテには患者の様々な副作用情報が記載されていたり,ソーシャルメディアテキストにはユーザーによる医薬品の使用方法が含まれています.言語処理技術を用いることで,大量の文書を直ちに処理することができるため,人手での情報抽出に比べ大幅な省力化ができることが期待されます.(共同研究先:京都大学附属大学病院,慶應大学薬学部)
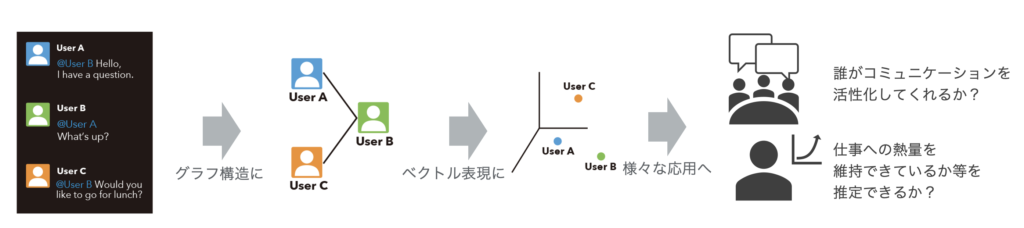
コミュニケーションデータから組織を科学する
組織で利用さているSlackを始めとしたInstant Messaging Systemのコミュニケーションデータを抽出し,人のコミュニケーションをグラフ構造によって表現することで,組織を活性化する人物の発見やWork Engagementの推定など,組織において活用できるマネージメント技術の研究を行っています.グラフ構造を持つデータに対して,グラフニューラルネットワークを始めとした様々な機械学習手法を用いています.(共同研究先:NTTドコモ)
脳卒中のリスク因子を自動抽出するシステム開発
死因の上位である脳卒中は症状を知覚しづらいですが,事前にリスクを把握できれば予防に役立ちます.脳卒中を発症させる恐れのある項目(リスク因子)には,血圧などの検査結果だけでなく,喫煙や過去の病歴などの電子カルテの自由記述にしかない情報も含まれます.この情報を医師が分析しやすい形式にするため,電子カルテからリスク因子を自動抽出するシステムを研究開発しています.
(共同研究先:国立循環器病研究センター,神戸市立医療センター中央市民病院)
実施中の臨床研究に関する情報公開・オプトアウトについて
ソーシャル・コンピューティング研究室では,今後の医療の発展につなげるため,診療情報を使って臨床研究を実施しています.これらの研究は本学の研究倫理審査委員会で承認されています.臨床研究の中でも,国が定めている倫理指針に基づいて,対象患者さまやご家族から直接同意をいただかないものがあります.この場合,あらかじめ内容をホームページで公開して,患者さまやご家族が情報を使うことを拒否できる機会を設けています.これを「オプトアウト」といいます.ご自身またはご家族の診療情報を研究で使ってほしくないと思った方は,研究室または,研究の担当者にご連絡ください.